This page lists all available artifacts for the paper and links to the source code of the implementation.
These files are made available for academic purposes only. Do not redistribute these files. Do not distribute direct links to these files, link to this page instead.
We do not claim authorship for the source code contained in the snapshot taken from C# repositories. Please respect the respective licence information for all included software.
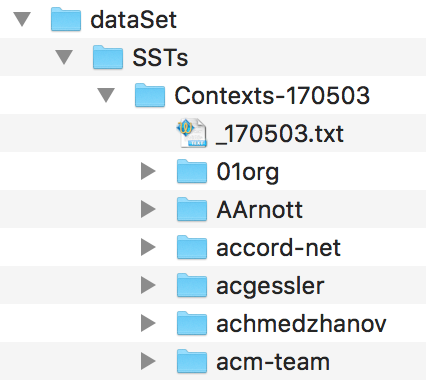
We provide all required data and tools to replicate the results presented in the paper. To achieve this, please start with downloading the "SSTs dataset repositories" (see links) and put them in the following folder structure.
As the next step, check out the Source Code. Once you have a copy of it on your machine, start the import in Eclipse (Import... -> General -> Existing Projects into Workspace) and select your check out folder.
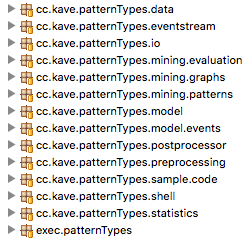
All projects should compile out of the box and you should have the following projects in your workspace now.
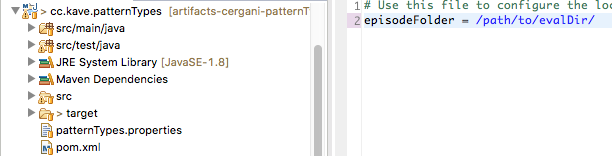
As the next step, copy or rename our template to patternTypes.properties and adapt the settings. Make sure that the entry points to a folder ends in a "/".
To get things started, you need to convert (preprocess) the SSTs representation, that you have just downloaded, to an event stream. The easiest way to achieve this is to open the "run_me" class in the exec.patternTypes project. The "FREQUENCY" field in this file indicates the minimum number of times that an event should apear in the event stream. By selecting only events that fulfill this frequency level, and filtering out the rest, we speed up the pattern mining and evaluation steps. If everything is configured correctly, you can start the class (Right click -> Run as... -> Java Application) and you will see a lengthy output of the preprocessed .zip files. The script will run for several minutes.
Once the script ends, you can replicate our experiments by loading the other classes in "run_me.java". Threshold analyzer will run the analyzes we use to decide on the threshold values pair (frequency, entropy) to run the episode miner. Calling the shell command script will execute the episode miner for outputting the episodes given the generated event stream. The final step is replicating our evaluations according to the three metrics described on the paper: expressiveness, consistency and generalizability.
(this page was last updated on January 7, 2019)